图
图的概念
在计算机程序设计中,图也是一种非常常见的数据结构。图论是一个非常大的话题,在数学上起源于哥尼斯堡七桥问题。
什么是图?
图是一种与树有些相似的数据结构。
- 实际上,在数学的概念上,树是图的一种。
- 我们知道树可以用来模拟很多现实的数据结构,比如:家谱/公司的组织架构等等。
图长什么样子呢?或者什么样的数据使用图来模拟更合适呢?
人与人之间的关系网
互联网中的网络关系

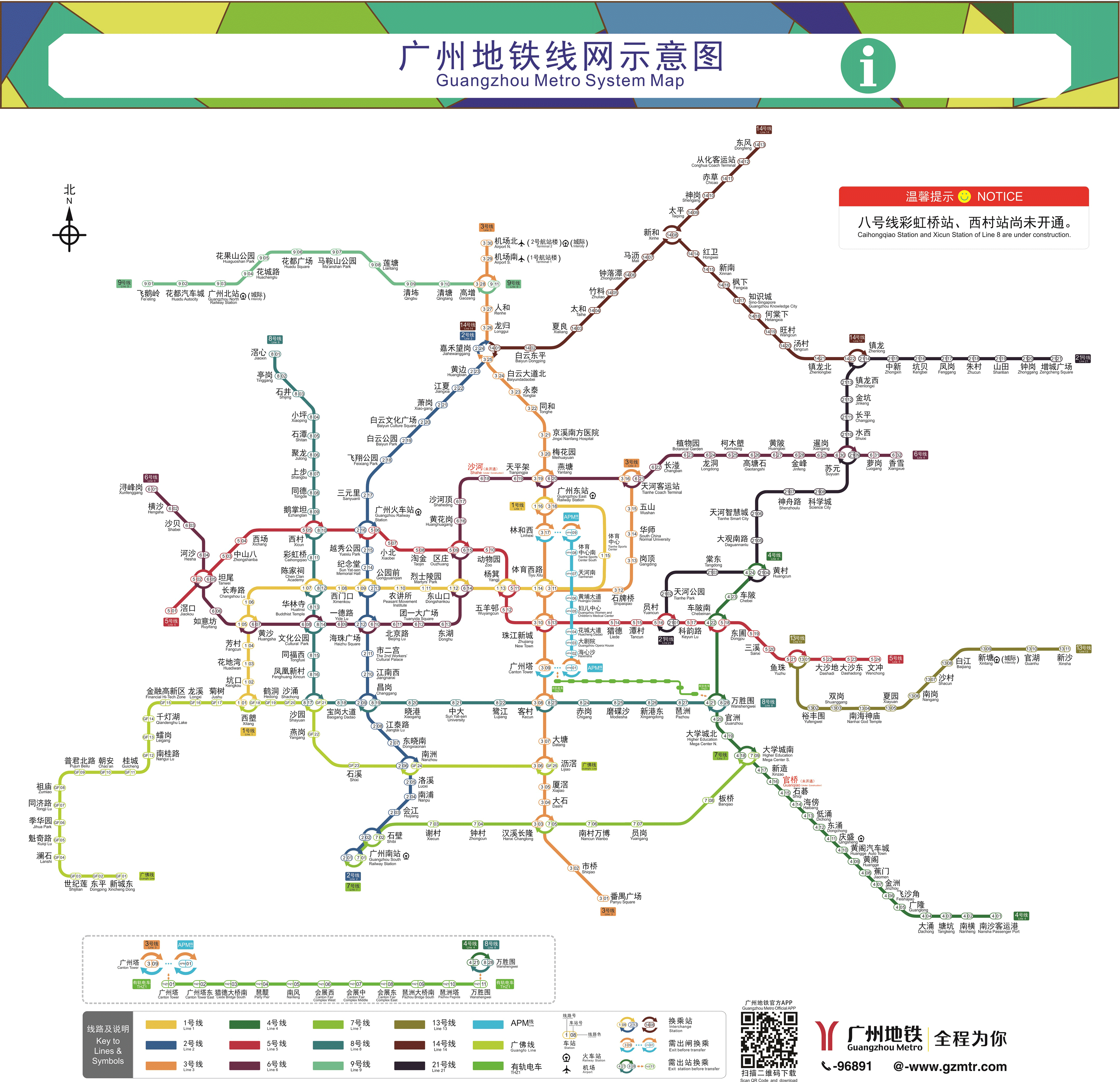
广州地铁图
什么是图呢?
- 我们会发现,上面的结点(其实图中叫顶点 Vertex)之间的关系,是不能使用树来表示(几叉树都不可以)。
- 这个时候,我们就可以使用图来模拟它们。
图通常有什么特点呢?
- 一组顶点:通常用 V (Vertex) 表示顶点的集合
- 一组边:通常用 E (Edge) 表示边的集合
- 边是顶点和顶点之间的连线
- 边可以是有向的,也可以是无向的。(比如 A --- B,通常表示无向。A --> B,通常表示有向)
图的术语
我们在学习树的时候,树有很多的其他术语,了解这些术语有助于我们更深层次的理解图。
图的术语也非常多,如果你找一本专门讲图的各个方面的书籍,会发现只是术语就可以占据一个章节。
这里,这里介绍几个比较常见的术语,某些术语后面用到的时候,再了解,没有用到的,不做赘述。
通过下图来了解图的术语:
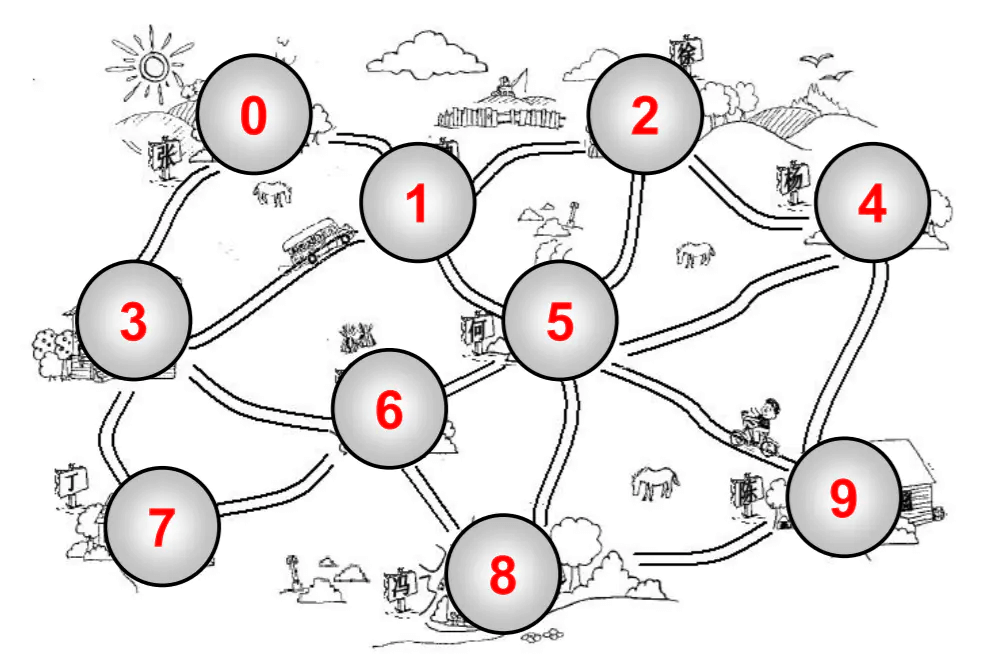
顶点
- 顶点刚才我们已经介绍过了,表示图中的一个结点。
- 比如地铁站中某个站/多个村庄中的某个村庄/互联网中的某台主机/人际关系中的人。
边
- 边表示顶点和顶点之间的连线。
- 比如地铁站中两个站点之间的直接连线,就是一个边。
- 注意:这里的边不要叫做路径,路径有其他的概念,后面会区分。
相邻顶点
- 由一条边连接在一起的顶点称为相邻顶点。
- 比如
0 - 1是相邻的,0 - 3是相邻的。0 - 2是不相邻的。
度
- 一个顶点的度是相邻顶点的数量
- 比如 0 顶点和其他两个顶点相连,0 顶点的度是 2
- 比如 1 顶点和其他四个顶点相连,1 顶点的度是 4
路径
- 路径是顶点
v1,v2...,vn的一个连续序列,比如上图中0 1 5 9就是一条路径。 - 简单路径:简单路径要求不包含重复的顶点。比如
0 1 5 9是一条简单路径。 - 回路:第一个顶点和最后一个顶点相同的路径称为回路。比如
0 1 5 6 3 0。
- 路径是顶点
无向图
- 上面的图就是一张无向图,因为所有的边都没有方向。
- 比如
0 - 1之间有边,那么说明这条边可以保证0 -> 1,也可以保证1 -> 0。
有向图
- 有向图表示的图中的边是有方向的。
- 比如
0 -> 1,不能保证一定可以1 -> 0,要根据方向来定。
无权图
- 如上图就是一张无权图,边没有携带权重。
- 上图中的边是没有任何意义的,不能说
0 - 1的边,比4 - 9的边更远或者用的时间更长。
带权图
- 带权图表示边有一定的权重
- 这里的权重可以是任意你希望表示的数据:比如距离或者花费的时间或者票价。
- 我们来看一张有向和带权的图:
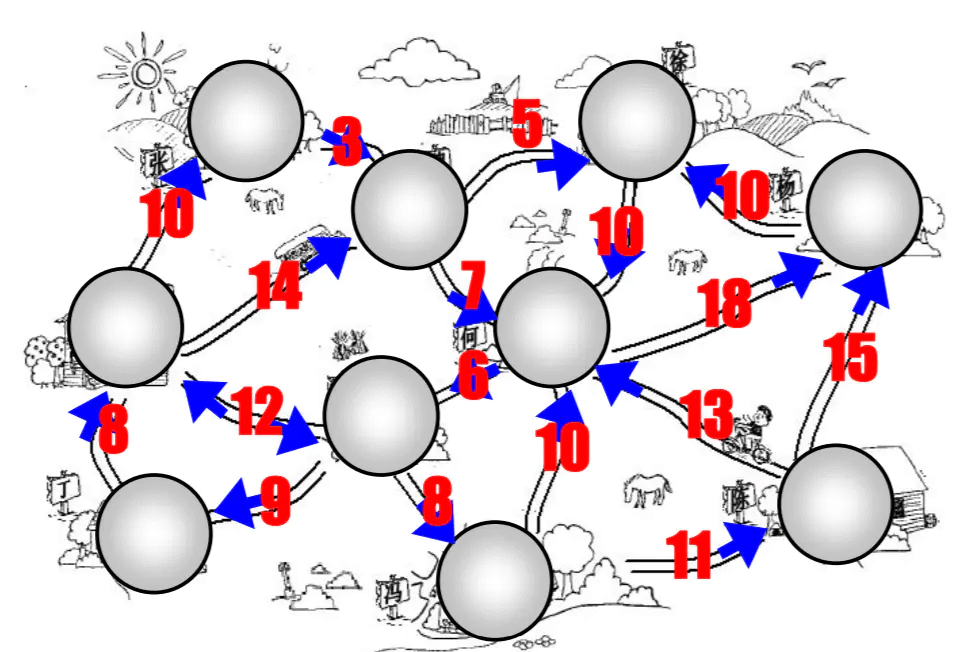
现实建模
对交通流量建模
- 顶点可以表示街道的十字路口,边可以表示街道.。
- 加权的边可以表示限速或者车道的数量或者街道的距离。
- 建模人员可以用这个系统来判定最佳路线以及最可能堵车的街道。
对飞机航线建模
- 航空公司可以用图来为其飞行系统建模。
- 将每个机场看成顶点,将经过两个顶点的每条航线看作一条边。
- 加权的边可以表示从一个机场到另一个机场的航班成本,或两个机场间的距离。
- 建模人员可以利用这个系统有效的判断从一个城市到另一个城市的最小航行成本。
图的表示
一个图包含很多顶点,另外包含顶点和顶点之间的连线(边),这两个都是非常重要的图信息,因此都需要在程序中体现出来。
顶点表示
顶点的表示相对简单
- 上面的顶点,我们抽象成了 1 2 3 4,也可以抽象成 A B C D。在后面的案例中,我们使用 A B C D。
- 那么这些 A B C D 我们可以使用一个数组来存储起来 (存储所有的顶点)。
- 当然,A B C D 有可能还表示其他含义的数据 (比如村庄的名字),这个时候,可以另外创建一个数组,用于存储对应的其他数据。
边的表示略微复杂,因为边是两个顶点之间的关系,所以表示起来会稍微麻烦一些。
邻接矩阵
概述
- 邻接矩阵让每个节点和一个整数向关联,该整数作为数组的下标值。
- 我们用一个二维数组来表示顶点之间的连接。
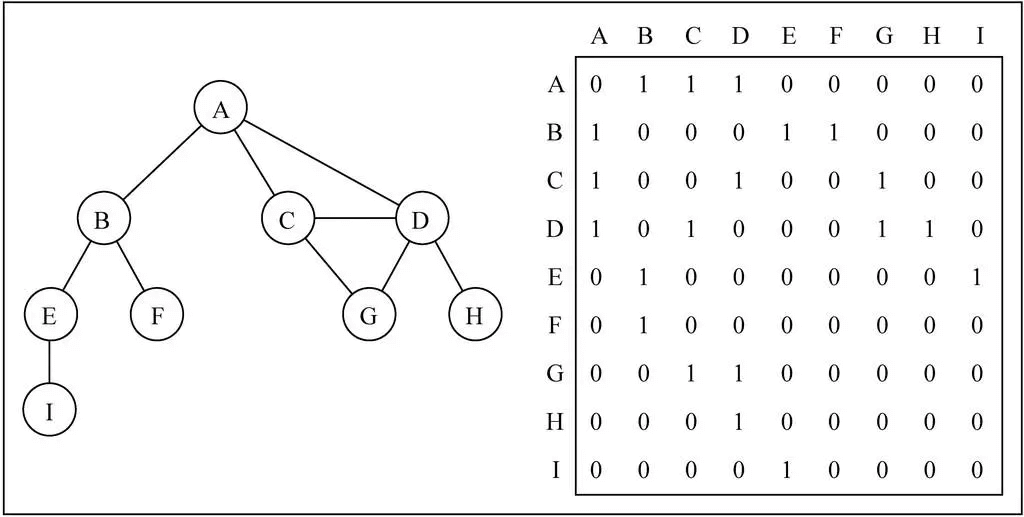
图片解析
- 在二维数组中,0 表示没有连线,1 表示有连线。
- 通过二维数组,我们可以很快的找到一个顶点和哪些顶点有连线。(比如 A 顶点,只需要 遍历第一行即可)
- 另外,A - A,B - B(也就是顶点到自己的连线),通常使用 0 表示。
邻接矩阵的问题
如果是一个无向图,邻接矩阵展示出来的二维数组,其实是一个对称图。 也就是 A -> D 是 1 的时候,对称的位置 D -> 1 一定也是 1。 那么这种情况下会造成空间的浪费,解决办法需自己去研究下。
如果图是一个稀疏图 那么矩阵中将存在大量的 0,这意味着我们浪费了计算机存储空间来表示根本不存在的边。 而且即使只有一个边,我们也必须遍历一行来找出这个边,也浪费很多时间。
邻接表
概述
- 邻接表由图中每个顶点以及和顶点相邻的顶点列表组成。
- 这个列表有很多中方式来存储:数组/链表/字典 (哈希表) 都可以。
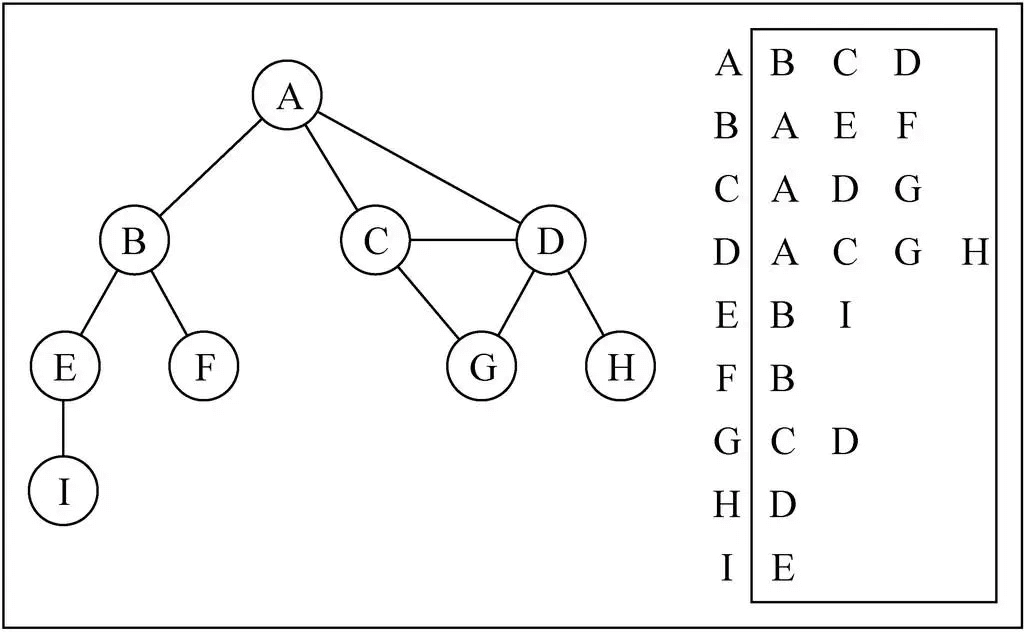
图片解析
比如我们要表示和 A 顶点有关联的顶点(边),A 和 B/C/D 有边,那么我们可以通过 A 找到 对应的数组/链表/字典,再取出其中的内容。
邻接表的问题
- 邻接表计算“出度”是比较简单的(出度:指向别人的数量,入度:指向自己的数量)
- 邻接表如果需要计算有向图的“入度”,那么是一件非常麻烦的事情。
- 它必须构造一个“逆邻接表”,才能有效的计算“入度”。而临街矩阵会非常简单。
图的封装
创建图类
先来创建 Graph 类,定义了两个属性:
vertexes用于存储所有的顶点,使用一个数组来保存。adjListadj 是 adjoin 的缩写,邻接的意思。adjList 用于存储所有的边,这里采用邻接表的形式。
class Graph {
constructor() {
this.vertexes = []; // 存储顶点
this.adjList = new Dictionay(); //存储边信息
}
}方法
添加顶点
向图中添加一些顶点。
- 将添加的顶点放入到数组中。
- 另外,给该顶点创建一个数组
[],该数组用于存储顶点连接的所有的边。(回顾邻接表的实现方式)
// 添加顶点
addVertex(val) {
// 添加点
this.vertexes.push(val)
// 添加点的关系 采用邻接矩阵法 结构用 Map
this.adjList.set(val, [])
}添加边
可以指定顶点和顶点之间的边。
- 添加边需要传入两个顶点,因为边是两个顶点之间的边,边不可能单独存在。
- 根据顶点 v 取出对应的数组,将 w 加入到它的数组中。
- 根据顶点 w 取出对应的数组,将 v 加入到它的数组中。
- 因为这里实现的是无向图,所以边是可以双向的。
// 添加边
addEdge(val1, val2) {
// 添加边需要传入两个顶点,因为边是两个顶点之间的边,边不可能单独存在。
// 这里实现的是无向图,所以这里不考虑方向问题
this.adjList.get(val1).push(val2)
this.adjList.get(val2).push(val1)
}toString 方法
为了能够正确的显示图的结果,就是拿出二维数组的每一项。
// 输出图结构
toString() {
let res = ''
for (let i = 0; i < this.vertexes.length; i++) {
res += this.vertexes[i] + "->"
let adj = this.adjList.get(this.vertexes[i])
for (let j = 0; j < adj.length; j++) {
res += adj[j] + ""
}
res += "\n"
}
return res
}测试代码
// 测试代码
let graph = new Graph();
// 添加顶点
let myVertexes = ["A", "B", "C", "D", "E", "F", "G", "H", "I"];
for (let i = 0; i < myVertexes.length; i++) {
graph.addVertex(myVertexes[i]);
}
// 添加边
graph.addEdge("A", "B");
graph.addEdge("A", "C");
graph.addEdge("A", "D");
graph.addEdge("C", "D");
graph.addEdge("C", "G");
graph.addEdge("D", "G");
graph.addEdge("D", "H");
graph.addEdge("B", "E");
graph.addEdge("B", "F");
graph.addEdge("E", "I");图的遍历
和其他数据结构一样,需要通过某种算法来遍历图结构中每一个数据。这样可以保证,在我们需要时,通过这种算法来访问某个顶点的数据以及它对应的边。
遍历的方式
图的遍历算法的思想在于必须访问每个第一次访问的节点,并且追踪有哪些顶点还没有被访问到。
有两种算法可以对图进行遍历
- 广度优先搜索 (Breadth-First Search, 简称 BFS)
- 深度优先搜索 (Depth-First Search, 简称 DFS)
这两种遍历算法,都需要明确指定第一个被访问的顶点。
遍历的注意点
- 完全探索一个顶点要求我们便查看该顶点的每一条边。
- 对于每一条所连接的没有被访问过的顶点,将其标注为被发现的,并将其加进待访问顶点列表中。
- 为了保证算法的效率:每个顶点至多访问两次。
两种算法的思想
- BFS 基于队列,入队列的顶点先被探索。
- DFS 基于栈,通过将顶点存入栈中,顶点是沿着路径被探索的,存在新的相邻顶点就去访问。
为了记录顶点是否被访问过,我们使用三种颜色来反应它们的状态。(或者两种颜色也可以)
- 白色表示该顶点还没有被访问。
- 灰色表示该顶点被访问过,但并未被探索过。
- 黑色表示该顶点被访问过且被完全探索过。
// 初始化顶点的颜色
initializeColor() {
// 白色:表示该顶点还没有被访问。
// 灰色:表示该顶点被访问过,但并未被探索过。
// 黑色:表示该顶点被访问过且被完全探索过。
let colors = []
for (let i = 0; i < this.vertexes.length; i++) {
colors[this.vertexes[i]] = "white"
}
return colors
}广度优先搜索 (BFS)
广度优先搜索算法的思路 广度优先算法会从指定的第一个顶点开始遍历图,先访问其所有的相邻点,就像一次访问图的一层。换句话说,就是先宽后深的访问顶点。
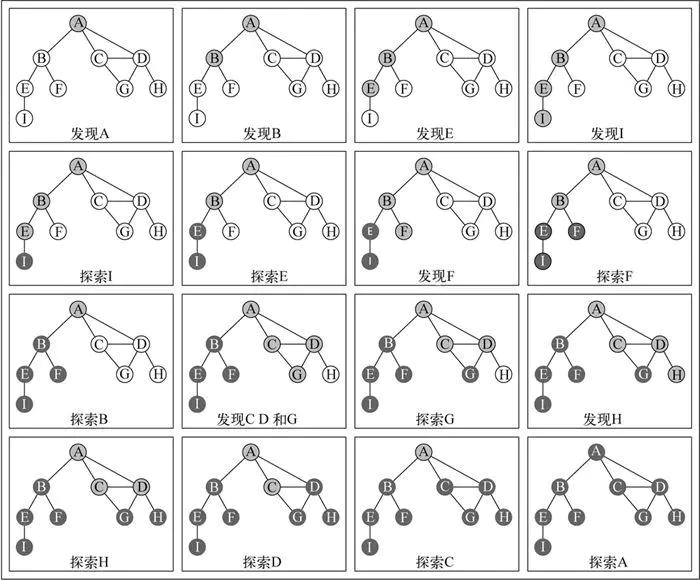
图解 BFS
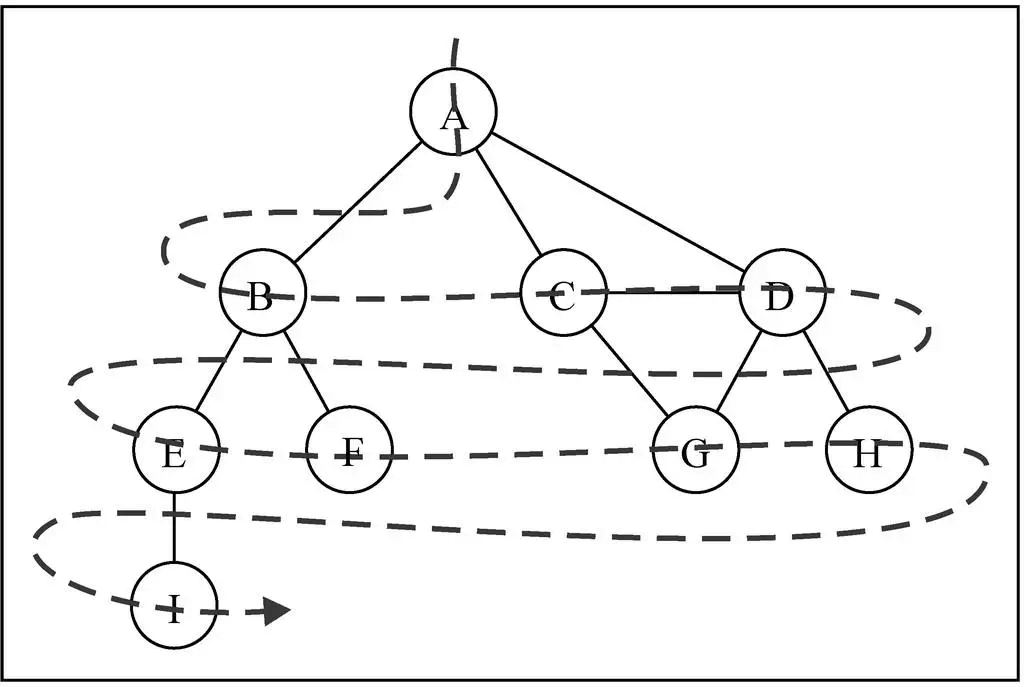
广度优先搜索的实现
- 创建一个队列 Q
- 将 v 标注为被发现的 (灰色), 并将 v 将入队列 Q
- 如果 Q 非空,执行下面的步骤:
- 将 v 从 Q 中取出队列
- 将 v 标注为被发现的灰色
- 将 v 所有的未被访问过的邻接点(白色),加入到队列中
- 将 v 标志为黑色
广度优先搜索的代码
js// 广度优先搜索 bfs(handle) { // 1.初始化颜色 let color = this._initializeColor() // 2. 创建队列 let queue = new Queue // 3. 将传入的顶点放入队列 queue.enqueue(this.vertexes[0]) // 4.依赖队列操作数据 队列不为空时一直持续 while (!queue.isEmpty()) { // 4.1 拿到队头 let qVal = queue.dequeue() // 4.2 拿到队头所关联(相连)的点并设置为访问中状态(灰色) let qAdj = this.adjList.get(qVal) color[qVal] = "gray" // 4.3 将队头关联的点添加到队尾 // 这一步是完成bfs的关键,依赖队列的先进先出的特点。 for (let i = 0; i < qAdj.length; i++) { let a = qAdj[i] if (color[a] === "white") { color[a] = "gray" queue.enqueue(a) } } // 4.5设置访问完的点为黑色。 color[qVal] = "black" if (handle) [ handle(qVal) ] } }测试代码
js// 调用广度优先算法 let result = ""; graph.bfs(graph.vertexes[0], function (v) { result += v + " "; }); console.log(result); // A B C D E F G H I
深度优先搜索 (DFS)
深度优先搜索的思路:
- 深度优先搜索算法将会从第一个指定的顶点开始遍历图,沿着路径知道这条路径最后被访问了。
- 接着原路回退并探索下一条路径。
- 图解 DFS
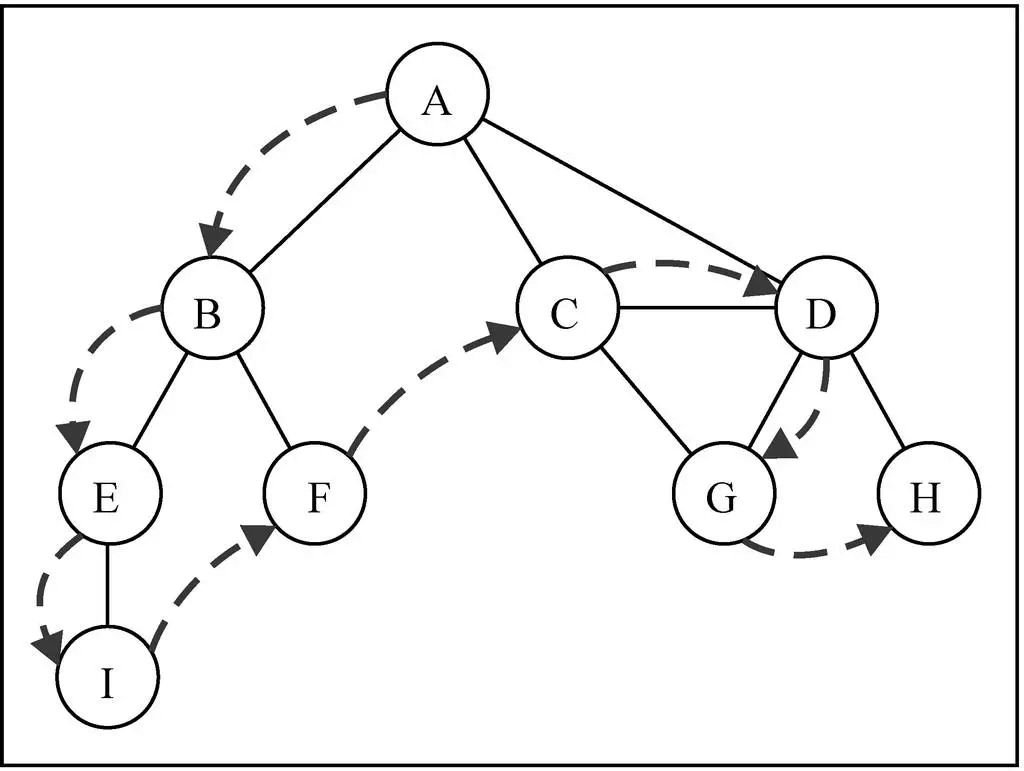
深度优先搜索算法的实现:
广度优先搜索算法我们使用的是队列,这里的深度优先搜索算法可以使用栈完成,也可以使用递归。(递归本质上就是函数栈的调用)
深度优先搜索算法的代码:
js// 深度优先搜索 dfs(handle) { // 1.初始化颜色 let color = this._initializeColor() // 2. 遍历所有顶点,开始访问 for (let i = 0; i < this.vertexes.length; i++) { if (color[this.vertexes[i]] === "white") { this._dfsVisit(this.vertexes[i], color, handle) } } } // dfs 的递归方法 这里直接使用函数的调用栈 _dfsVisit(val, color, handle) { // 1. 将颜色设置为访问中 color[val] = "gray" // 2. 执行相应的回调 if (handle) { handle(val) } // 3. 拿与该点相邻的点,对每个点操作 let adj = this.adjList.get(val) for (let i = 0; i < adj.length; i++) { let w = adj[i] // 如果相邻点未未访问状态,开始访问。 if (color[w] === "white") { this._dfsVisit(w, color, handle) } } // 4. 处理完后设置为访问过点。 color[val] = "black" }测试代码
js// 调用深度优先算法 result = ""; graph.dfs(function (v) { result += v + " "; }); // 输出深度优先 console.log(result); //A B E I F C D G H递归的代码较难理解一些,这副图来帮助理解过程: